🚀 I have sorted out several projects I have done in recent months
✍️ In recent months, I have done some interesting projects, including ViT on CIFAR-10, Simple ML, ASR, etc.
🎙️ Auto Speech Recognition
I dove into the world of Automatic Speech Recognition (ASR) by building a Large Vocabulary Continuous Speech Recognition (LVCSR) system using the Kaldi toolkit.
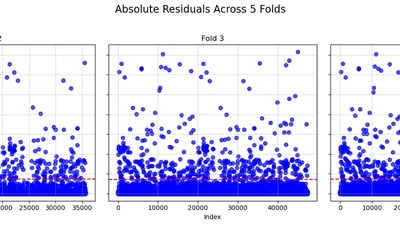
Simple-ML
TripDataset Machine Learning Project This project is a complete implementation of machine learning pipelines applied to the TripDataset, focusing on data preprocessing, …
•
1 min read
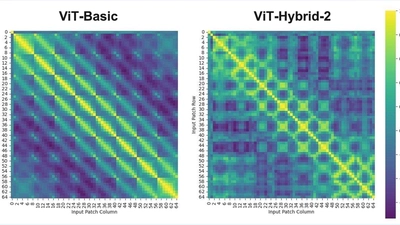
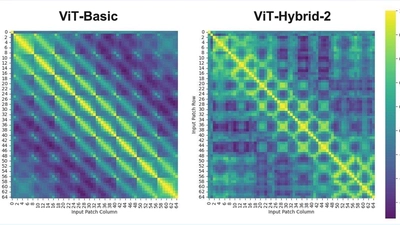
🧩 ViT on CIFAR-10
This project is a complete implementation of Vision Transformer (ViT) applied to small-scale datasets (especially CIFAR-10), including extensive exploration.
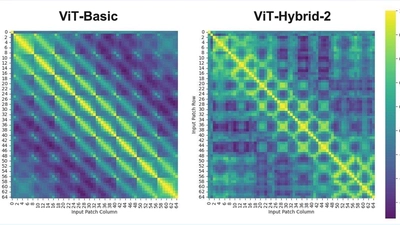
ViT on CIFAR-10
ViT-torch: Vision Transformer on CIFAR-10 (PyTorch) This project is a complete implementation of Vision Transformer (ViT) applied to small-scale datasets (especially CIFAR-10), …
•
1 min read
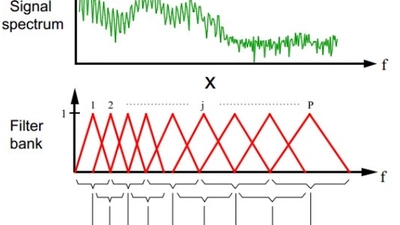
🎙️ Voice Activity Detection
I conducted extensive experiments comparing frame division methods and model performances, with rich visualizations.
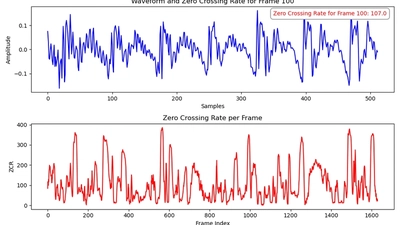
🎉 I have opensourced my VAD project recently
📈 I conducted extensive experiments comparing frame division methods and model performances, with rich visualizations.
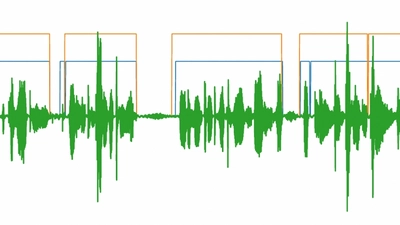
Voice Activity Detection
🎯 Voice Activity Detection (VAD), or voice endpoint detection, identifies time segments in an audio signal containing speech. This is a critical preprocessing step for automatic …
•
1 min read
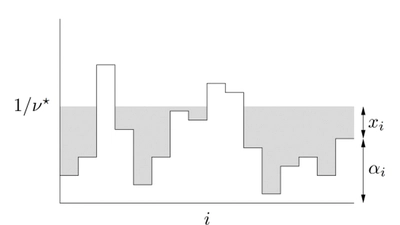
Water-filling Problem
Establishment and solution of mathematical optimization model This project is a lab of the course “Linear Optimization and Convex Optimization”. It discusses a classic optimization …
•
1 min read