RAG-TA
Dec 12, 2025
·
2 min read
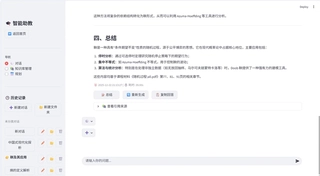
RAG-TA: RAG-based Intelligent Teaching Assistant System
The RAG Intelligent Teaching Assistant System is an intelligent teaching assistance platform based on Multimodal Retrieval-Augmented Generation (Multimodal RAG), specifically designed for educational scenarios. The system integrates the following core functions:
🤖 Intelligent Question Answering System
- Multimodal Understanding: Supports complex question answering with text and images, capable of understanding charts, formulas, and image content in course materials.
- Contextual Retrieval: Precise semantic retrieval based on the ChromaDB vector database.
- Hybrid Retrieval: Combines dense vector retrieval and sparse retrieval (BM25) to improve retrieval accuracy.
- Source Tracing: Automatically annotates the source file and page number of the answer, ensuring information traceability.
📚 Knowledge Base Management
- Multi-format Support: Supports various formats including PDF, PPTX, DOCX, TXT, MD, and images.
- Intelligent Indexing: Automatically extracts text and image content to build a multimodal vector index.
- Incremental Updates: Intelligently detects file changes and updates only the changed parts, improving efficiency.
- Folder Management: Supports hierarchical directory structure for easy organization of course materials.
💬 Conversation Management
- History: Complete conversation history saving and management.
- Multiple Answer Options: Supports multiple answer versions for the same question, allowing users to switch between them.
- Folder Classification: Supports conversation folder management for easy course classification.
- Thinking Mode: Visualizes the AI reasoning process to help understand the answer logic.
🖼️ Multimodal Interaction
- Image Understanding: Automatically extracts and describes image content in PDFs/PPTXs.
- Real-time Upload: Supports users uploading images and documents for instant question answering.
- Visual Question Answering: Provides comprehensive answers combining image content and text knowledge.
{kind=link}