EADP: Entropy-Aware Dense Visual Token Pruning
 GitHub Repo: EADP
GitHub Repo: EADPWhy We Built EADP
Modern vision-language models can reason over rich visual inputs, but this ability often comes with a long sequence of visual tokens. More visual tokens usually mean more computation, more memory pressure, and higher inference latency. Visual token pruning is a natural way to make these models faster: keep the tokens that matter, remove the redundant ones, and let the downstream LLM reason over a compact visual representation.
That sounds simple, but in practice the pruning step becomes fragile when the instruction is dense, the visual clue is tiny, or the token budget is tight. Our ECCV 2026 work, Combating Textual Noise and Redundancy: Entropy-Aware Dense Visual Token Pruning, studies this failure mode and proposes EADP, a lightweight plug-and-play pruning framework.
- Project page: EADP
- Publication page: Combating Textual Noise and Redundancy
- Code: SJTU-DeepVisionLab/EADP
What Goes Wrong in Visual Token Pruning?
We found that the failure is not only about assigning a bad score to a token. It is also about how the final selected token set represents the image.
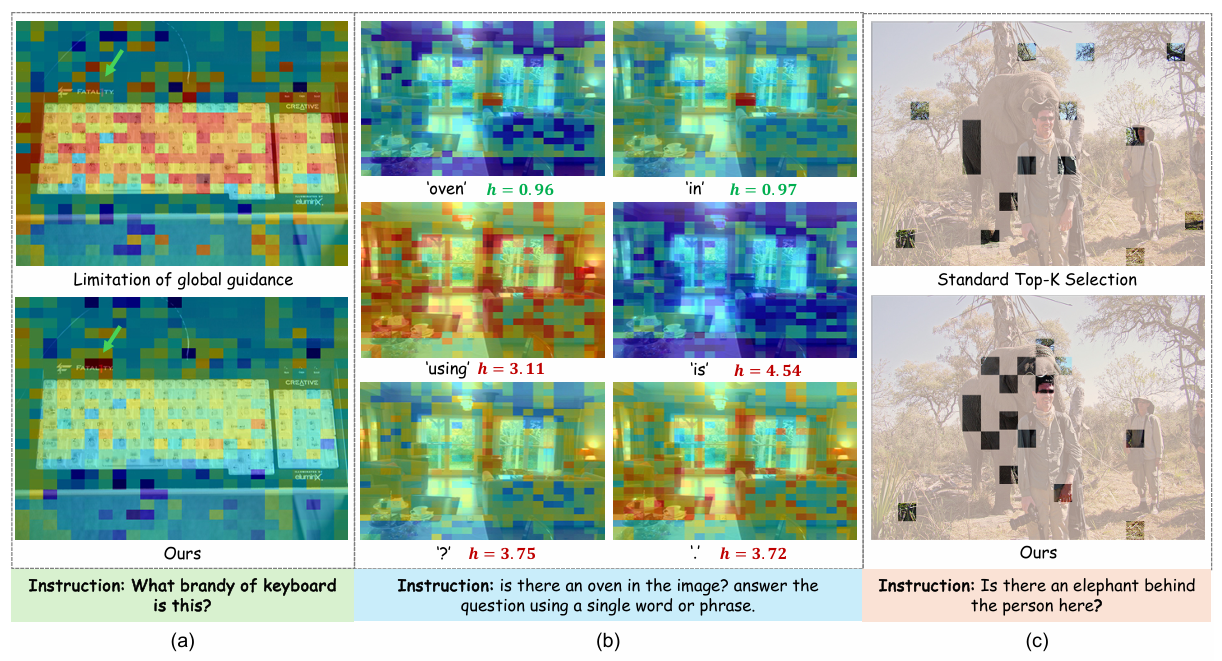
There are three issues that motivated EADP:
- Global guidance is too coarse. A single global text feature can miss fine-grained details and may even attend to background regions.
- Dense guidance contains textual noise. Dense text-token guidance is more expressive, but function words and punctuation may produce high-entropy, spatially dispersed responses that become a noise floor.
- Top-K selection is redundant. Standard Top-K selection tends to repeatedly sample local maxima, leaving other semantic regions uncovered.
This led us to treat visual token pruning as a structured compression problem rather than a simple score-ranking problem.
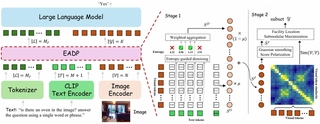
The EADP Idea
EADP compresses a full set of visual tokens into a compact subset before the downstream LLM consumes them. The core idea is to first make instruction relevance more reliable, then make token selection less redundant.
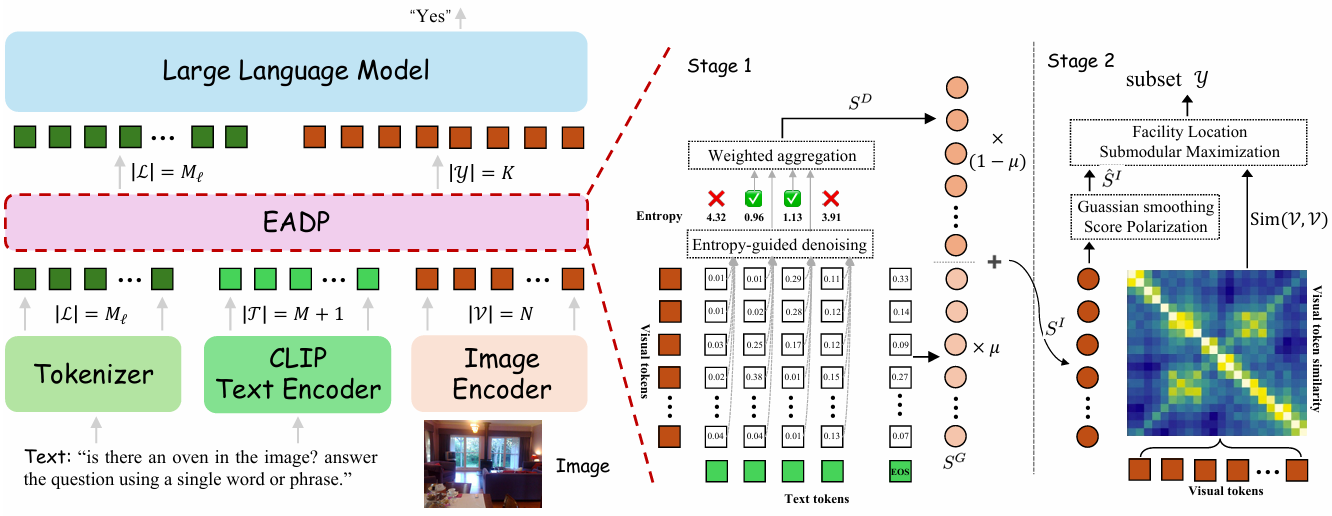
Stage 1: Entropy-Aware Dense Scoring
EADP computes dense cross-modal similarities between non-EOS text tokens and visual tokens. It then estimates the spatial entropy of each text token’s similarity distribution.
Low-entropy tokens tend to point to localized and meaningful visual regions. High-entropy tokens are more likely to behave like dispersed textual noise. By filtering or down-weighting high-entropy guidance and fusing the remaining dense signal with the global EOS signal, EADP builds a more robust instruction relevance map.
Stage 2: Structured Token Selection
Once the score map is more reliable, EADP still avoids naive Top-K selection. It first applies spatial smoothing and score polarization to preserve local structure and sharpen core visual entities. Then it formulates selection as a facility-location submodular maximization problem, encouraging the retained tokens to be representative and non-redundant.
In short, EADP tries to keep the tokens that are both important and diverse enough to cover the image.
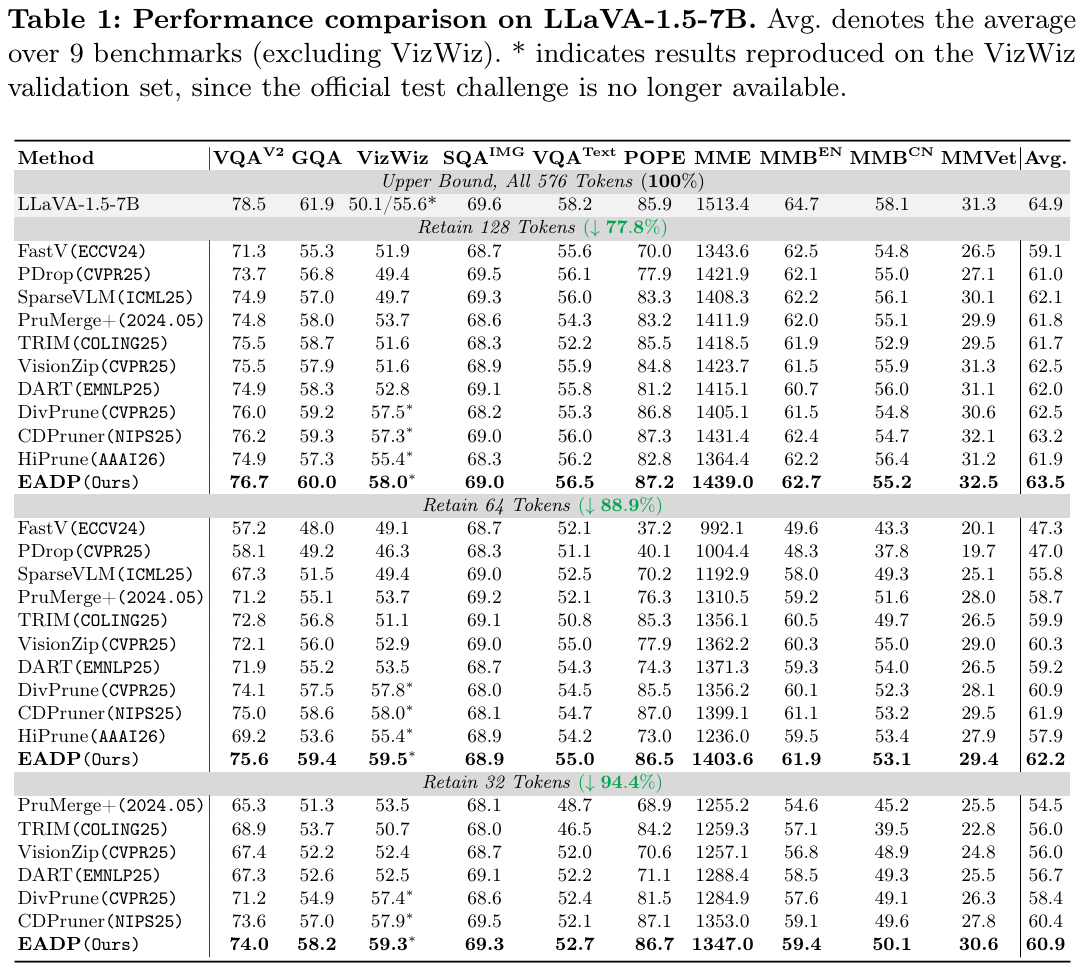
Experimental Snapshot
Below are several result snapshots from the project page. The full details are available in the paper and repository.
LLaVA-1.5
LLaVA-1.6
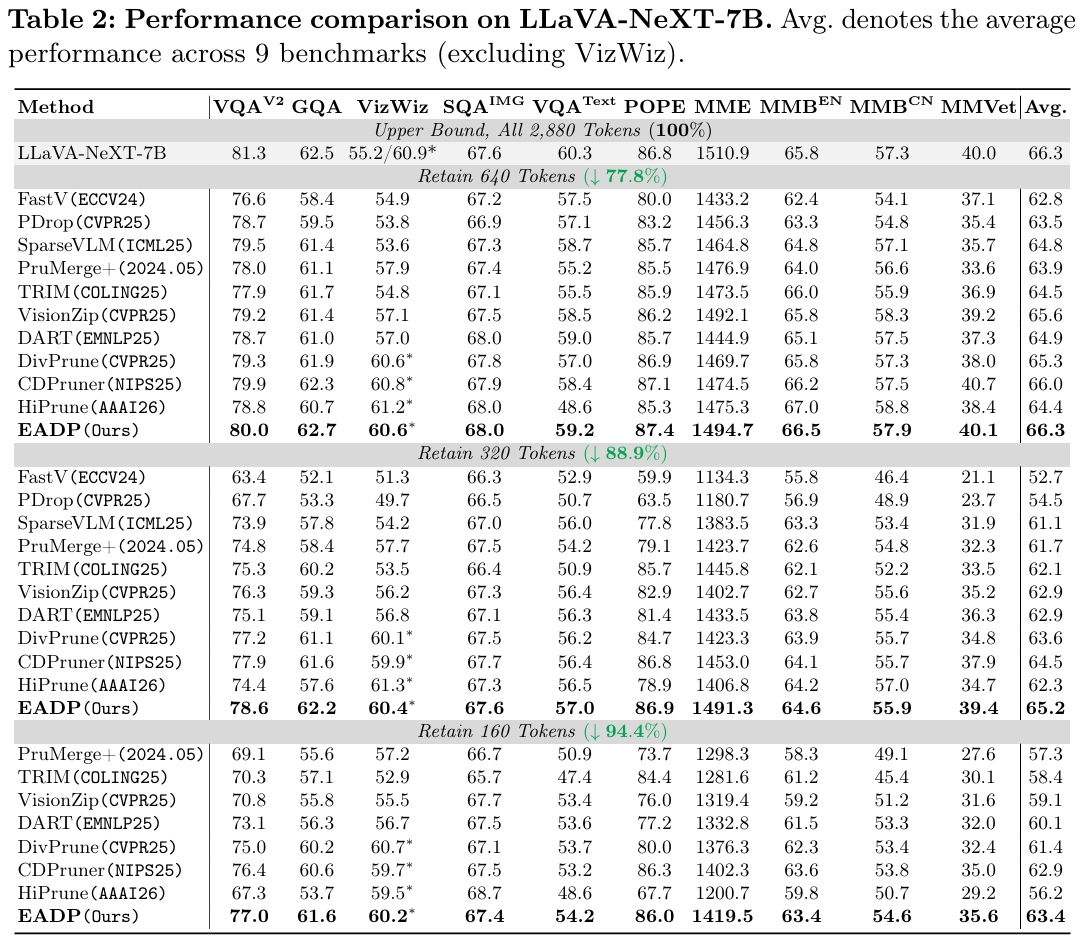
Qwen2.5-VL
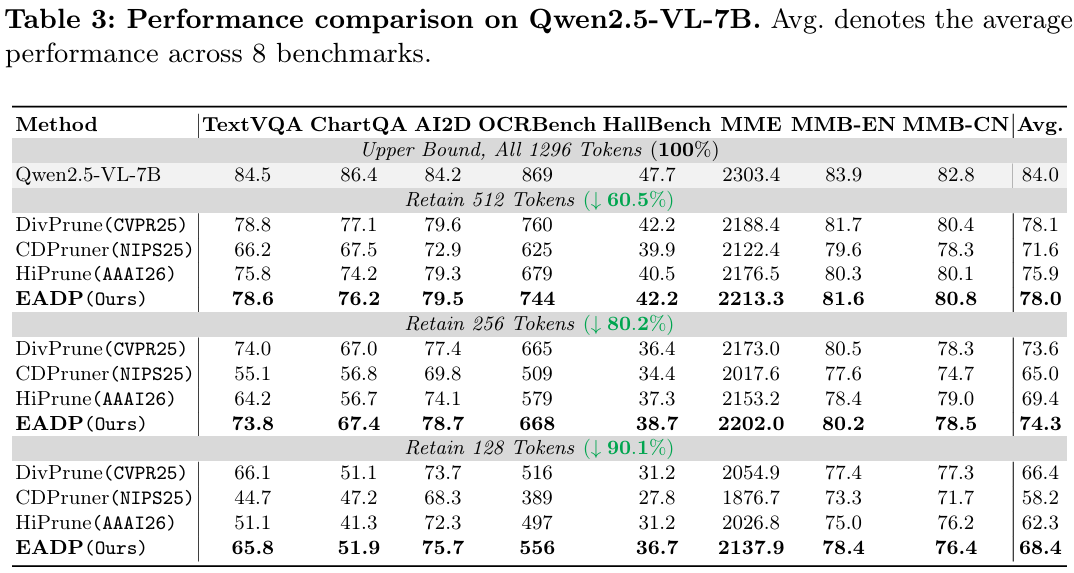
LLaVA-Video
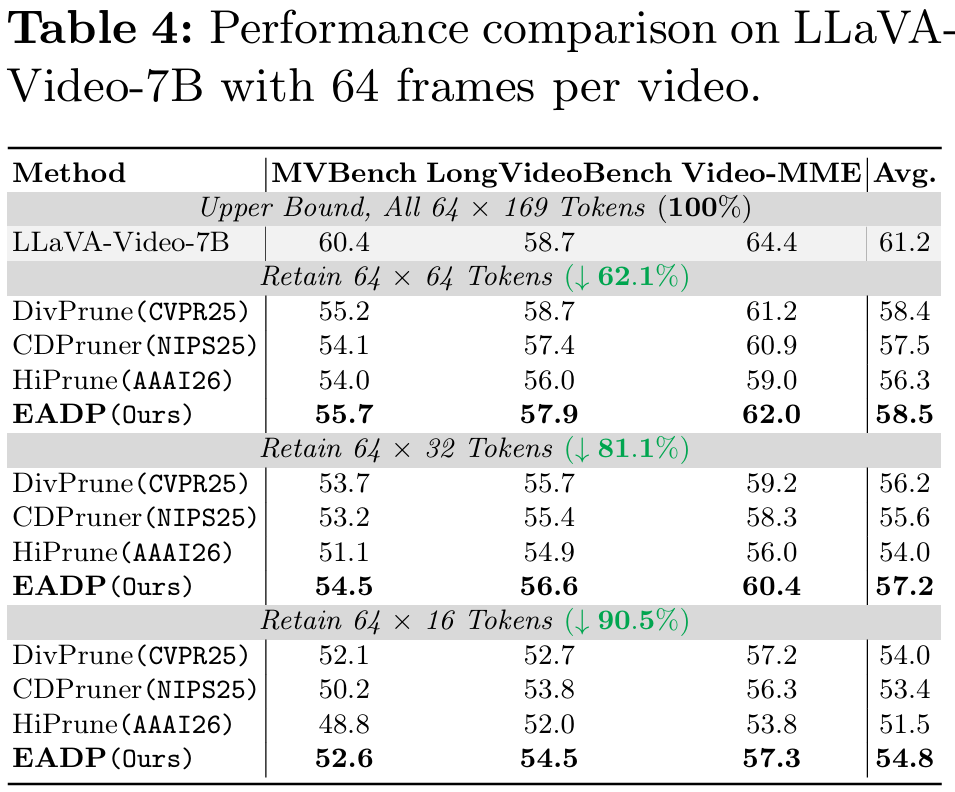
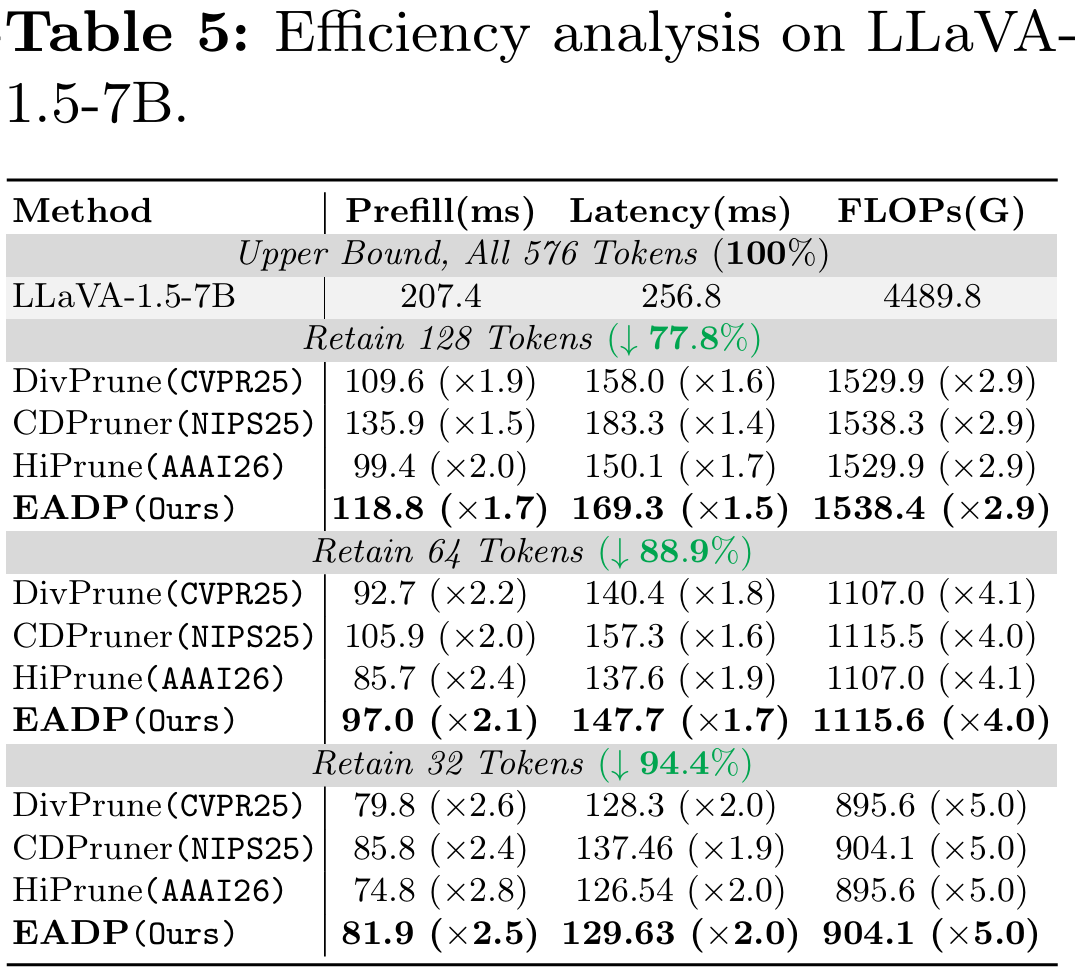
Efficiency Analysis
Try the Code
We have released the repository here:
git clone https://github.com/SJTU-DeepVisionLab/EADP.git
If this work is useful to you, please consider giving the repo a star: EADP
Citation
@inproceedings{wang2026eadp,
title = {Combating Textual Noise and Redundancy: Entropy-Aware Dense Visual Token Pruning},
author = {Wang, Xuehui and Yang, Xuankun and Shen, Wei},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
year = {2026},
url = {https://github.com/SJTU-DeepVisionLab/EADP}
}
{kind=link}